工作流持续排队
工作流事件触发后会以消息的形式先进入 Kafka 消息队列,再由工作流消费服务进行读�取消息进行处理流程。
遇到工作流持续排队时,首先需要先区分平台内工作流虽然排队量大但也在陆续消费,还是一直排队并无消费。
以如下两种常见情况为例:
- 工作流排队量大但也在陆续消费
- 工作流一直排队并无消费
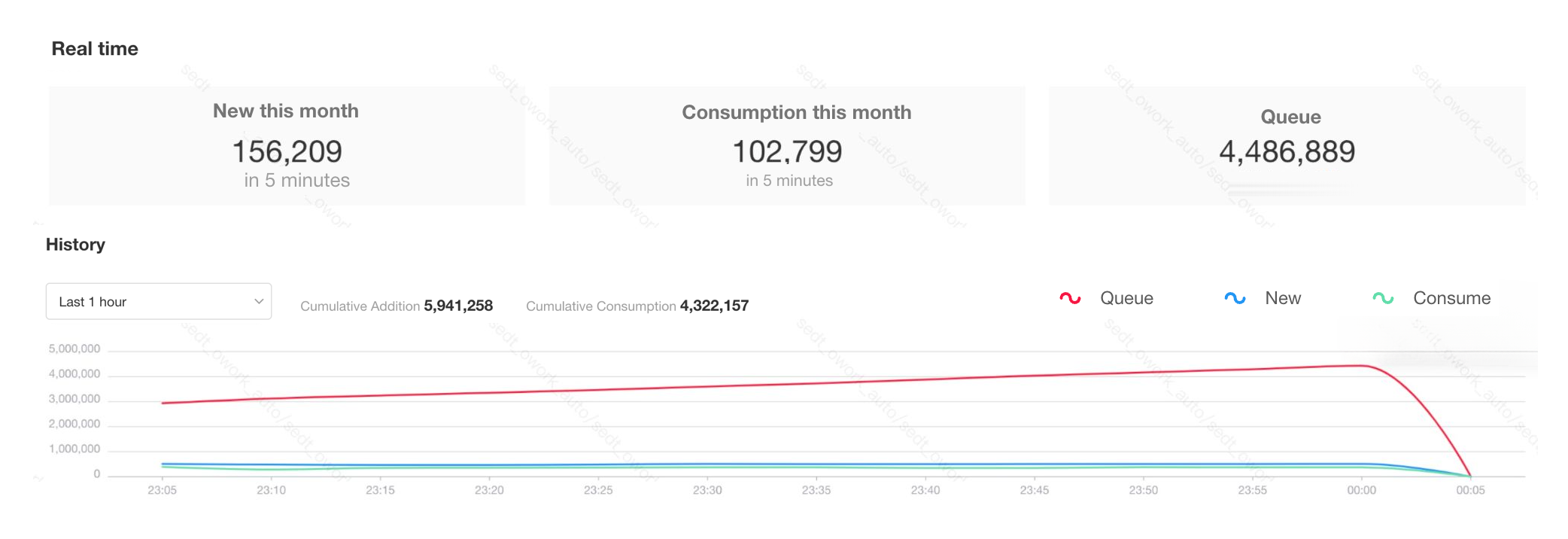
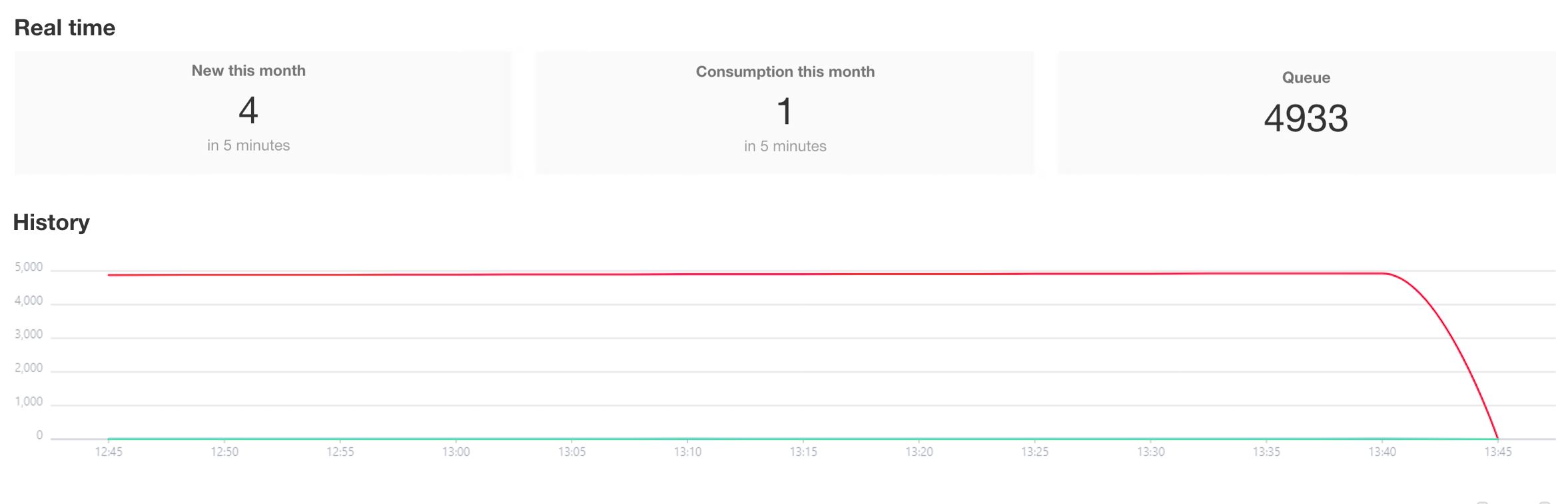
工作流排队量大但也在陆续消费
在工作流监控页面看下是否有个别流程排队数字非常高,如有数十万、百万等这种排队量较大的流程,可能是因为业务人员没能配置好触发逻辑或者死循环等原因造成工作流触发量大。
消费能力可能受多种影响有处理上限,比如每分钟正常可以处理一万条流程,但实际可能触发了数十万条流程,此时触发流程较多,流程不能快速消费完,就呈现了排队的现象。
例如有个别工作流在排队数十万条甚至更高时,造成了所有工作流排队严重,如确认到这种排队量大的流程不需要其再消费,应在非暂停状态下直接关闭对应工作流。
-
工作流直接关闭后,排队中的消息会快速消费(不走工作流中的节点逻辑),这样可以让排队中的工作流尽快得到处理。
-
如果这种排队量大的工作流需要消费,可以先暂停,等待业务空闲期间再开启。
如果没有误触发排队较多的工作流,请登陆服务器检查资源的占用情况。可以使用 top 命令查看当前服务器与各进程 CPU、内存的资源实时占用。
-
占用 CPU 较大的进程是
mongod进程,通常是因为有慢查询导致,处理方式参见慢查询优化帮助文档。 -
占用 CPU 较大的进程是
dotnet或java进程,通常是工作流节点中的逻辑较为复杂,会连带关联服务资源占用上升。- 如果当前服务器资源满载可以选择扩容或暂停逻辑复杂的工作流等业务低峰期再运行。
- 如是基于 Kubernetes 部署的集群模式,可以在资源还有一定冗余的情况动态扩容资源占用高的服务实例。
工作流一直排队并无消费
在所有工作流一直排队并无消费时,通常为服务器磁盘满,或者队列组件 Kafka 服务异常导致。
-
在服务器上通过
df -Th命令查看当前系统盘与数据盘的使用率。 -
检查 Kafka 服务是否正常:
- 单机模式
- 集群模式
查看存储组件容器健康检查日志
docker logs $(docker ps | grep mingdaoyun-sc | awk '{print $1}')- 输出日志中正常全为 INFO 级别,如有 Kafka 服务一直重启代表当前 Kafka 服务状态异常,可先尝试整体重启服务,如 Kafka 依旧无法启动则参见清空 kafka 异常数据的处理方式。
登录部署 Kafka 的服务器,通过
systemctl status kafka命令可以检查当前服务器的 Kafka 服务状态。正常应处于长期 running 状态,如一直频繁重启或处于 failed 状态则代表服务状态异常,应进一步分析处理。
如果是因为磁盘满、Kafka 服务异常这种等原因造成触发的工作流没能写入 Kafka 队列,则历史触发的 "排队中" 流程不会再进行消费。
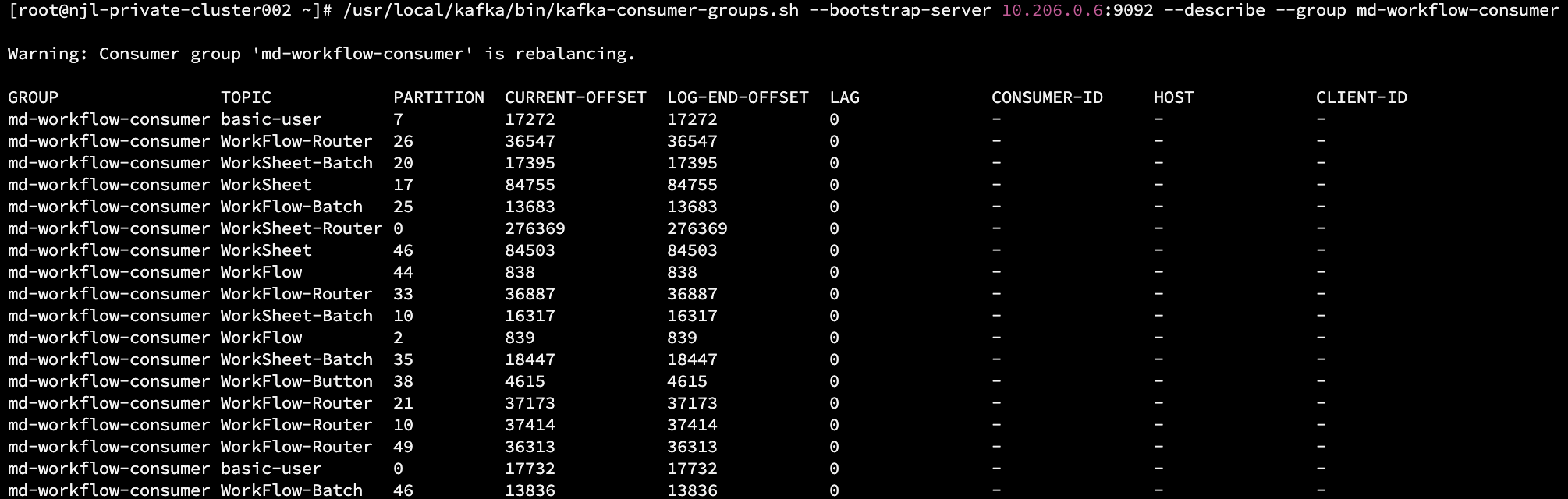
还有一种极少数的情况可能是 Kafka 消费组处于 rebalance 状态,主要是受慢流程导致超时、或者消费服务实例受资源影响发生重启等�情况,会造成消费组重平衡。
可参考下方命令查看各 Topic 分区实际的消息堆积情况与检查当前是否处于 rebalancing 状态:
- 单机模式
- Kubernetes 集群模式
-
进入存储组件容器
docker exec -it $(docker ps | grep mingdaoyun-sc | awk '{print $1}') bash -
执行查看 Kafka 查看 md-workflow-consumer 消费组的消费情况命令
/usr/local/kafka/bin/kafka-consumer-groups.sh --bootstrap-server ${ENV_KAFKA_ENDPOINTS:=127.0.0.1:9092} --describe --group md-workflow-consumer- 如提示
Error: Executing consumer group command failed due to null可以点击下载 Kafka 的安装包,然后将安装包上传到部署服务器并拷贝到 mingdaoyun-sc 容器内,随后解压文件,使用新安装包下的bin/kafka-consumer-groups.sh工具执行上述命令。
- 如提示
在部署 Kafka 的服务器执行查看 md-workflow-consumer 消费组的消费情况命令
/usr/local/kafka/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group md-workflow-consumer
- 如提示
Connection to node -1 (/127.0.0.1:9092) could not be established. Broker may not be available.可以将 127.0.0.1 换成本机内网服务器 IP 后再尝试执行
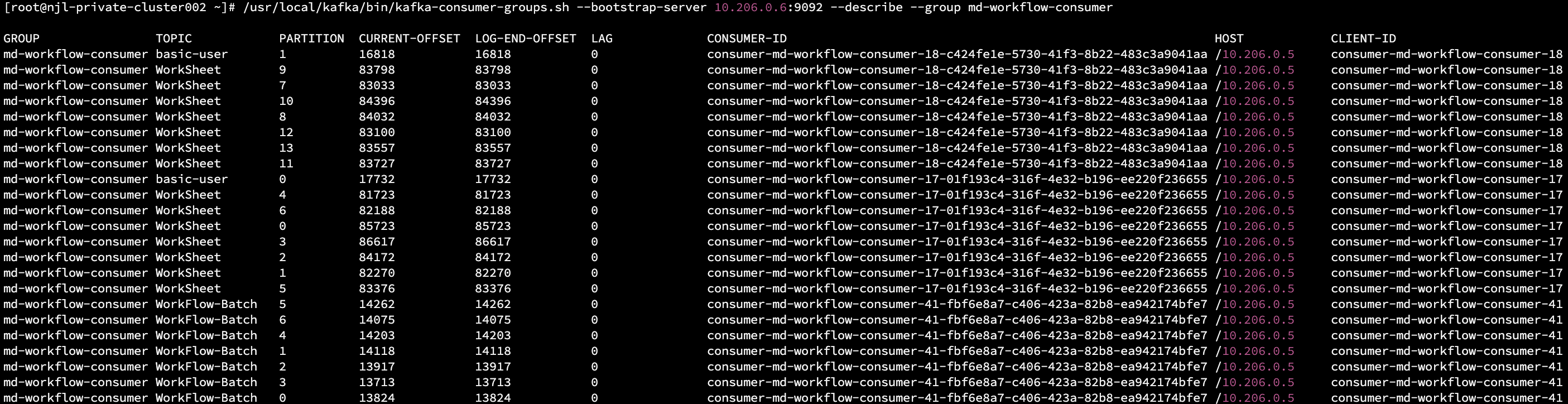
正常输出应如下图所示,如提示 Warning: Consumer group 'md-workflow-consumer' is rebalancing. 则代表消费组正在 rebalance 中。
- 正常状态
- rebalancing 状态
-
LAG 列代表当前 Topic 分区的消息堆积数量
-
工作流常使用的 Topic 名称:
-
WorkFlow:主流程执行
-
WorkFlow-Process:子流程工作流执行
-
WorkFlow-Router:工作流执行慢队列
-
WorkFlow-Batch:批量工作流执行
-
WorkFlow-Button:按钮工作流执行
-
WorkSheet:行记录验证是否触发工作流
-
WorkSheet-Router:行记录慢队列验证是否触发工作流
-
如长时间处于 rebalancing 状态,可以尝试重启工作流消费服务,重启方式如下:
- 单机模式
- Kubernetes 集群模式
-
进入微服务容器
docker exec -it $(docker ps | grep -E 'mingdaoyun-community|mingdaoyun-hap' | awk '{print $1}') bash -
在容器内执行单独重启工作流消费服务命�令
source /entrypoint.sh && workflowconsumerShutdownsource /entrypoint.sh && workflowrouterconsumerShutdown
重启工作流消费服务
kubectl rollout restart deploy workflowconsumer
kubectl rollout restart deploy workflowrouterconsumer