Continuous Queuing of Workflows
After a workflow event is triggered, it enters the Kafka message queue in the form of a message, and is then consumed by the workflow consumption service for processing.
When encountering a persistent workflow queue within the platform, the initial step is to differentiate between a scenario where the queue is large but items are being processed gradually and one where the queue remains stagnant with no consumption.
Consider the following two scenarios:
- Workflow queued and consumed
- Workflow queued but not consumed
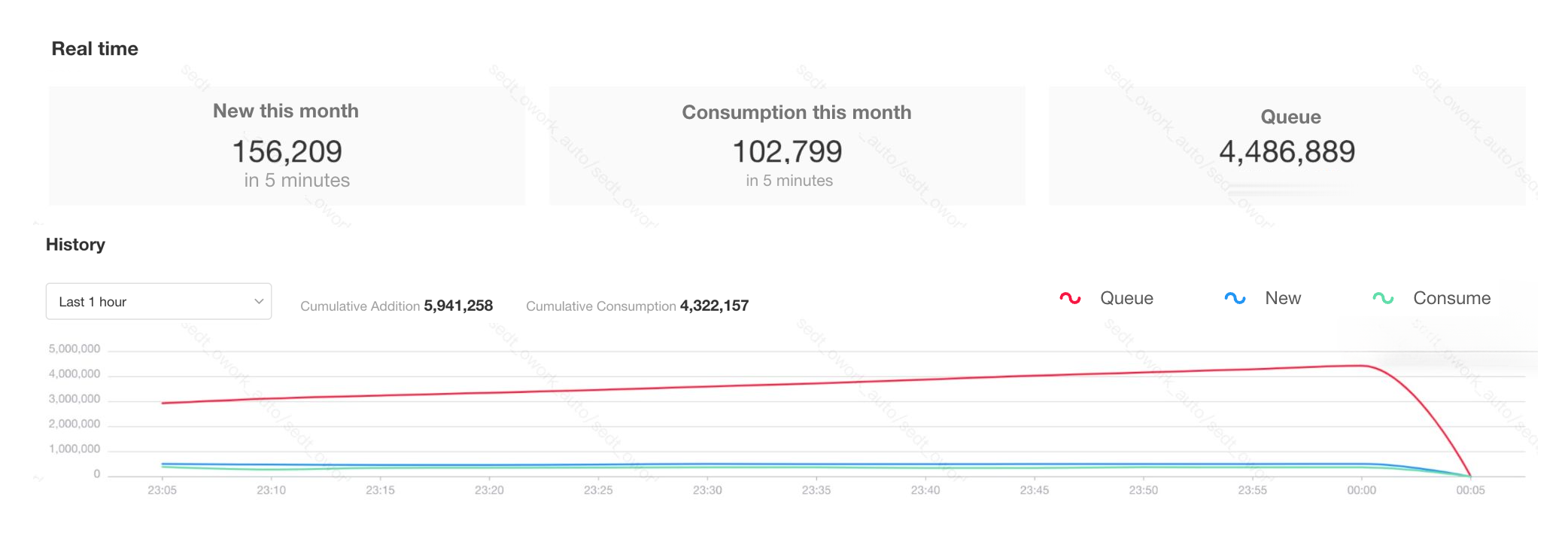
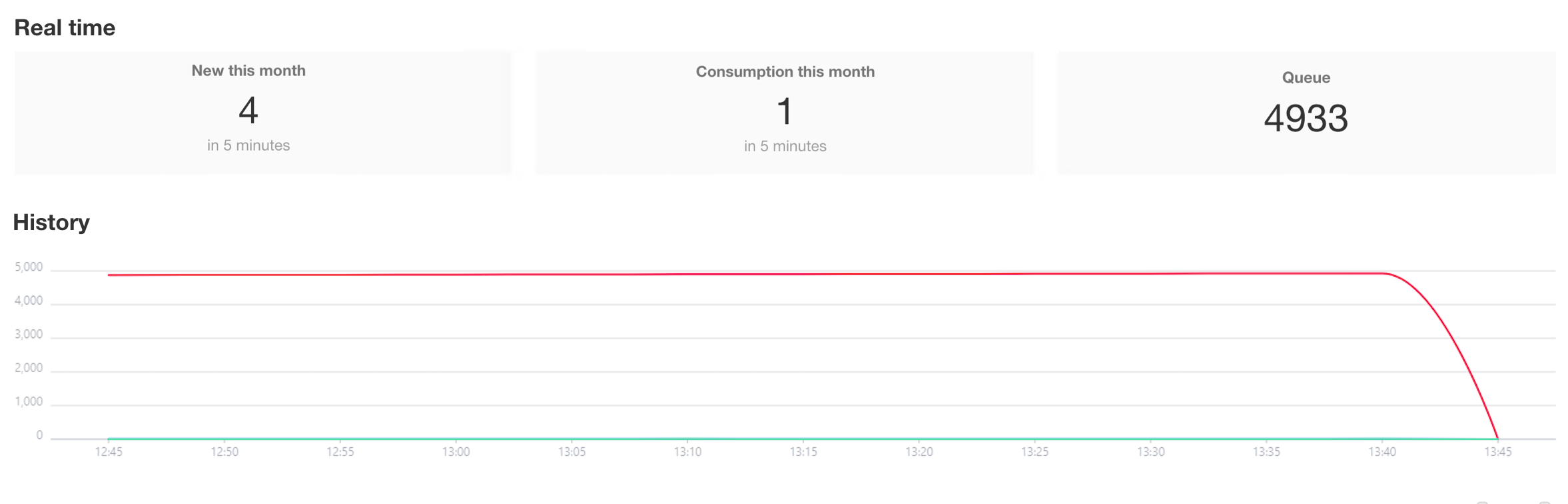
Workflow queued and consumed
Check the monitoring page of the workflow to see if there are workflows with a very large queue, such as tens of thousands or millions of workflows. This may be due to misconfigured trigger logic by business personnel or loops causing a high volume of workflow triggers.
Consumption capacity may be affected by various factors. For example, while the system can normally process ten thousand workflows per minute, there may be instances where hundreds of thousands of workflows are triggered, resulting in a large number of workflows being queued up without being quickly consumed.
For example, when a few workflows have a queue of tens of thousands or more, causing severe queuing for all workflows, if it is confirmed that these workflows with large queues do not need to be processed again, they should be directly closed in a non-paused state.
-
When a workflow is closed directly, the workflows in the queue will be quickly consumed (without going through the nodes logic in the workflow), allowing them to be processed as soon as possible.
-
If the workflows with a large queue need to be consumed, they can be paused first and then re-started during business downtime.
If there is no unintended triggering of workflows with high queue volumes, please log in to the server and check resource usage. You can use the top command to view the real-time CPU and memory usage of the server and its processes.
-
If the process consuming a significant amount of CPU is the
mongodprocess, it is usually caused by slow queries. For resolution, refer to the slow query optimization. -
If the process consuming a significant amount of CPU is a
dotnetorjavaprocess, it is typically due to complex logic in workflow nodes, which can also increase resource usage for related services.- If the server resources are fully utilized, you may choose to scale out or postpone running workflows with complex logic to periods of low business activity.
- If it is a Kubernetes-based cluster deployment, and there is some resource redundancy, you can dynamically scale up the service instances with high resource usage.
Workflow queued but not consumed
When the workflow is continuously queued but not consumed, it is usually due to a full server disk or an issue with the Kafka service.
-
Use the
df -Thcommand on the server to check the usage of the system disk and data disk. -
Check if the Kafka service is running properly:
- Standalone Mode
- Cluster Mode
Check the health check logs of the storage component container.
docker logs $(docker ps | grep mingdaoyun-sc | awk '{print $1}')
- If the log output is normal, it will be all INFO. If the Kafka service keeps restarting continuously, it means the current Kafka service is abnormal. You can try restarting the service as a whole first. If Kafka still cannot start, clear the Kafka error data.
Login to the server where Kafka is deployed, and use the systemctl status kafka command to check the current status of the Kafka service on the server.
It should normally be in a running state. If it keeps restarting frequently or is in a failed state, it indicates an abnormal service status.
If the triggered workflows were unable to be written to the Kafka queue due to reasons such as a full disk or Kafka service issues, the history "queued" workflows triggered will no longer be consumed.
An extremely rare possibility is that the Kafka consumer group is in a rebalance state. This is mainly caused by slow processes resulting in timeouts, or consumer service instances being affected by resource issues and restarting, which in turn triggers consumer group rebalancing.
You can use the following command to check the actual message accumulation status in each topic partition and whether the system is currently in a rebalancing state:
- Standalone Mode
- Kubernetes Cluster Mode
-
Enter the container of the storage component
docker exec -it $(docker ps | grep mingdaoyun-sc | awk '{print $1}') bash -
Execute the command to view the consumption of the md-workflow-consumer consumer group
/usr/local/kafka/bin/kafka-consumer-groups.sh --bootstrap-server ${ENV_KAFKA_ENDPOINTS:=127.0.0.1:9092} --describe --group md-workflow-consumer- If prompted with
Error: Executing consumer group command failed due to null, you can click to download the Kafka installation package, then upload the installation package to the deployment server and copy it into the mingdaoyun-sc container. After that, unzip the file and use thebin/kafka-consumer-groups.shfrom the new installation package to execute the above command.
- If prompted with
On the server where Kafka is deployed, execute the command to view the consumption of the md-workflow-consumer consumer group
/usr/local/kafka/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group md-workflow-consumer
- If prompted with
Connection to node -1 (/127.0.0.1:9092) could not be established. Broker may not be available., you can try replacing 127.0.0.1 with the local intranet server IP and then retry the execution.
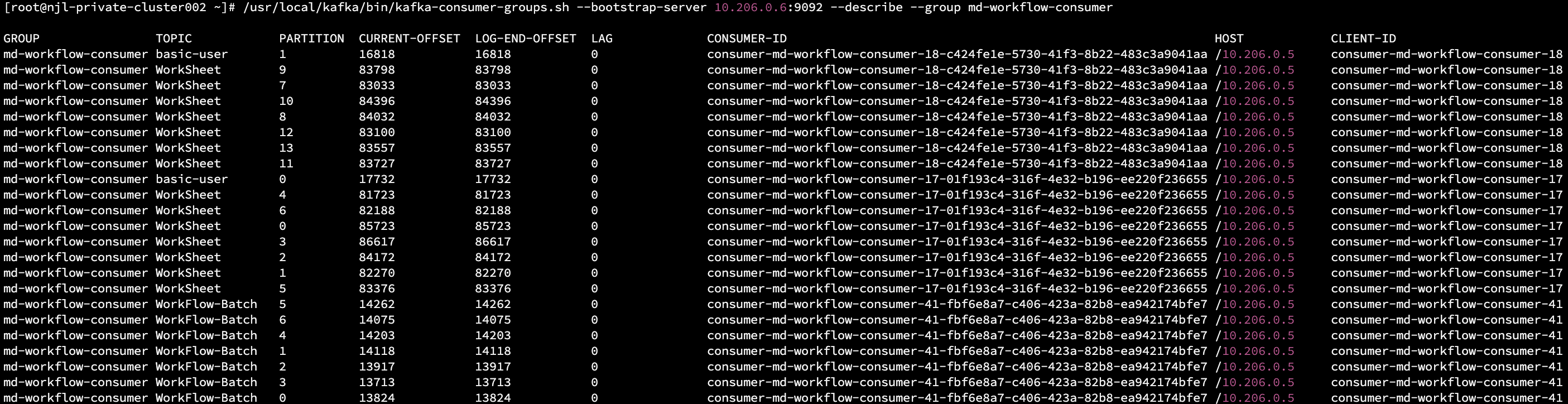
The normal output is as follow. If prompted with Warning: Consumer group 'md-workflow-consumer' is rebalancing., it means the consumer group is currently rebalancing.
- Normal State
- Rebalancing
-
The LAG column represents the number of messages currently accumulated in the Topic partition.
-
Commonly used Topic names in workflows:
-
WorkFlow:Main workflow execution
-
WorkFlow-Process:Sub-workflow execution
-
WorkFlow-Router:Slow queue for workflow execution
-
WorkFlow-Batch:Bulk workflow execution
-
WorkFlow-Button:Button-triggered workflow execution
-
WorkSheet:Row record validation for triggering workflows
-
WorkSheet-Router:Slow queue row record validation for triggering workflows
-
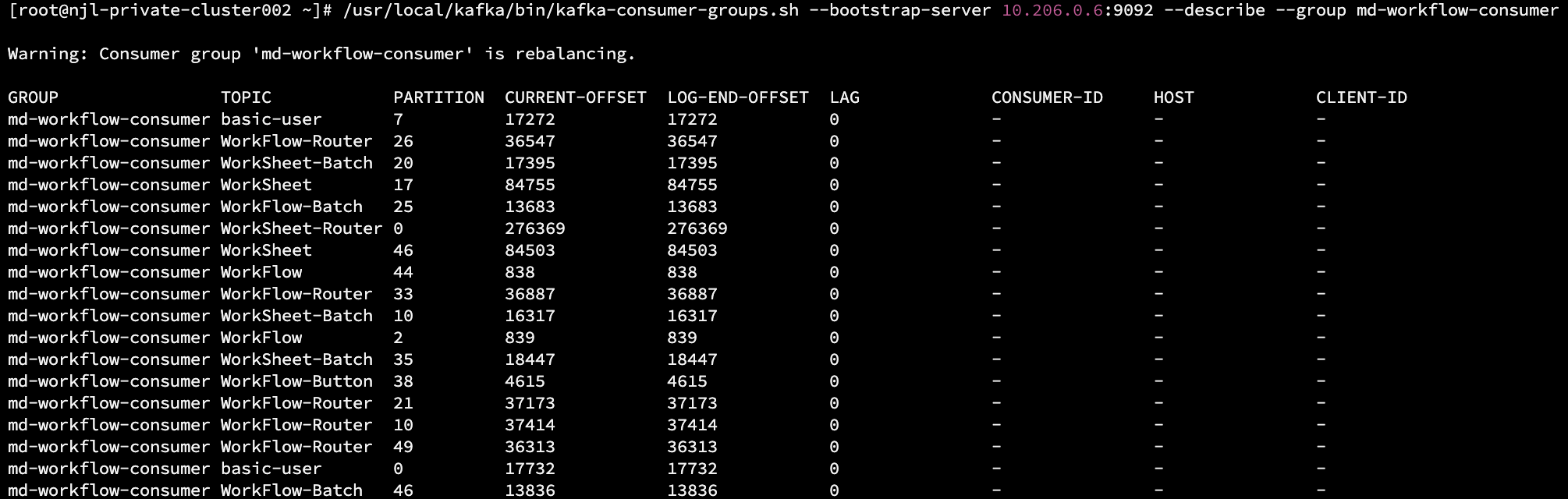
If it remains in a rebalancing state for a long time, you can try restarting the workflow consumer service with the following steps:
- Standalone Mode
- Kubernetes Cluster Mode
-
Enter the container of the microservice
docker exec -it $(docker ps | grep -E 'mingdaoyun-community|mingdaoyun-hap' | awk '{print $1}') bash -
Execute the command to restart the workflow consumer service individually inside the container
source /entrypoint.sh && workflowconsumerShutdownsource /entrypoint.sh && workflowrouterconsumerShutdown
Restart the workflow consumer service.
kubectl rollout restart deploy workflowconsumer
kubectl rollout restart deploy workflowrouterconsumer