MongoDB 慢查询优化
什么是慢查询
慢查询是指执行时间较长的查询操作。
通常,数据库查询都会迅速的完成,但当表的数据量非常庞大(例如数十万行或更多)时,频繁地从这些表中查询会增加数据库的负担。这可能导致硬件资源的过度使用,例如CPU占用率较高、内存使用率过大、系统负载过高。因此,查询操作会变得“慢”,单次查询耗时数百毫秒甚至数秒钟。
为了优化查询性能,我们可以采取一些措施,例如:
- 索引优化:创建适当的索引以加速查询。
- 查询优化:编写高效的查询方式,避免不必要的计算和数据传输。
- 硬件优化:增加服务器的硬件资源,以处理更大的数据集。
- 多集群存储数据:参考应用数据多集群存储与行记录多集群存储,增加纵向能力,减轻业务持续增长对单一数据库持续带来压力。
索引优化
在 HAP 社区中,有一位同学以自己见解写了一篇 MongoDB的索引优化 帖子,这里作为引用,大家可以参考。
索引的基本知识与索引创建管理也可以参考 HAP 帮助文档。
查询优化
对于数十万行或更多数据量的工作表,在做批量筛选、查询时,要注重查询方式,提前创建查询条件中涉及到的字段索引。
通常,最佳的查询方式是精确查询,比如使用 “等于” 条件。尤其是当字段值不重复且已建立索引时,这种查询方式的效率极高。
另外,也有一些查询方式是不会走索引的:
-
筛选条件中,不等于、不包含、开头不是等否定条件,都不会走索引
-
筛选条件中包含、为空的筛选条件,不走索引
-
筛选条件中,增加 “或” 的筛选条件,不走索引
-
工作表右上角的搜索功能为正则查询方式,不走索引
-
选项类型字段,如果单个选项值占比高,搜索不会走索引
-
文本字段勾选了支持拼音排序时,排序索引不生效
对于数据量庞大的工作表,尽量减少使用以上列举的大批量查询条件,可以降低数据库负载。
硬件优化
-
扩容 CPU 核数:
- MongoDB 是一个多线程应用程序,因此增加 CPU 核数可以提高并发处理能力。
- 选择高性能的多核 CPU,以便更好地处理查询和写入操作。
-
扩容内存:
- 内存对 MongoDB 性能至关重要。增加内存可以提高缓存效率,减少磁盘 I/O。
- MongoDB 使用内存作为工作集缓存,因此足够的内存可以减少磁盘读取次数,提高查询性能。
-
使用高性能 SSD 磁盘:
- SSD 磁盘比传统的机械硬盘(HDD)更快,具有更低的访问延迟和更高的吞吐量。
- MongoDB 的默认存储引擎是 WiredTiger,它对 SSD 磁盘的支持非常好。
慢查询索引优化实践
查找日志
在 MongoDB 进程占用 CPU 较高的情况下,通常是大量慢查询语句占用,可以通过查看 MongoDB 日志,找到对应慢查询语句,进一步优化。
- HAP 单机模式
- HAP 集群模式
MongoDB 日志默认路径:/data/mingdao/script/volume/data/logs/mongodb.log
如自定义过数据路径,请在实际的数据路径下寻找
请到�部署 MongoDB 的服务器上寻找 mongodb.log 文件
由官方部署通常会在如下路径:/data/logs/mongodb/mongodb.log
日志分析示例
在日志最新的内容中,可以看到很多的日志内容,这里挑选两个示例进行分析
示例一
2023-03-08T15:50:43.075+0800 I COMMAND [conn38294] command mdwsrows.ws63083dafdf551460042a73 command: find { find: "ws63083dafdf551460042a73", filter: { 63e0bafdafa62a19751ee00: "4115fd005", status: 1.0 }, sort: { utime: -1 }, projection: { _id: 0, status: 0, sharerange: 0, wsutime: 0, keywords: 0, discussunreads: 0, users: 0, owners: 0, unreads: 0 }, limit: 1 } planSummary: COLLSCAN keysExamined:0 docsExamined:381665 hasSortStage:1 cursorExhausted:1 numYields:2981 nreturned:1 reslen:1456 locks:{ Global: { acquireCount: { r: 5964 } }, Database: { acquireCount: { r: 2982 } }, Collection: { acquireCount: { r: 2982 } } } protocol:op_query 1023ms
重点关注字段含义:
- mdwsrows:库
- ws63083dafdf551460042a73:表名称
- command:具体操作命令细节
- find:查询条件
- 63e0bafdafa62a19751ee00:字段(控件ID)
- COLLSCAN:全表扫描
- docsExamined:381665:表记录总数
- op_query 1023ms:耗时
日志含义:查询 ws63083dafdf551460042a73 表中字段 63e0bafdafa62a19751ee00 值为 4115fd005 的数据,全表扫描总耗时 1023 毫秒
添加索引建议:给字段 63e0bafdafa62a19751ee00 添加索引
示例二:
2023-04-25T08:12:10.736+0000 I COMMAND [conn1696545] command mdwsrows.ws629f242342bb5f060f3da4 command: aggregate { aggregate: "ws629f242342bb5f060f3da4", pipeline: [ { $match: { 62c9c6076c186b941274189f: "90123c1d-1498-43a4-b96b-001a69fd4bb9", 62ccea346123b943f747acf: { $in: [ "0cda5ce1-32139-4c52-b2f4-b324545ccfd1", "2e0e92ec-a935-43fa-a4a3-5fbdee85c0c0" ] }, $and: [ { 62c9c6076c186b941274189f: "90123c1d-1498-43a4-b96b-001a69fd4bb9" }, { 62ccea346123b943f747acf: { $in: [ "0cda5ce1-32139-4c52-b2f4-b324545ccfd1", "2e0e92ec-a935-43fa-a4a3-5fbdee85c0c0" ] } } ], status: 1.0 } }, { $group: { _id: "null", count: { $sum: 1 } } } ], cursor: {}, $db: "mdwsrows", lsid: { id: UUID("d09a5780-0115-4182-8eb2-9de7d76fd834") }, $clusterTime: { clusterTime: Timestamp(1682410329, 2213), signature: { hash: BinData(0, 6B87048FC23C103EE23E4E026B9B246CD45F), keyId: 720303239516495874 } } } planSummary: COLLSCAN keysExamined:0 docsExamined:468021 cursorExhausted:1 numYields:3656 nreturned:1 queryHash:97671D20 planCacheKey:97671D20 reslen:282 locks:{ ReplicationStateTransition: { acquireCount: { w: 3658 } }, Global: { acquireCount: { r: 3658 } }, Database: { acquireCount: { r: 3658 } }, Collection: { acquireCount: { r: 3658 } }, Mutex: { acquireCount: { r: 2 } } } storage:{ data: { bytesRead: 12110018, timeReadingMicros: 11575 } } protocol:op_msg 1043ms
重点关注字段含义:
- mdwsrows:库
- ws629f242342bb5f060f3da4:表名称
- command:具体操作命令细节
- aggregate:聚合操作
- $match:过滤条件
- 62c9c6076c186b941274189f:字段(控件ID)
- 62ccea346123b943f747acf:字段(控件ID)
- $in:包含
- COLLSCAN:全表扫描
- docsExamined:468021表记录总数
- op_msg 1043ms:耗时
日志含义:在 mdwsrows 数据库中的 ws629f242342bb5f060f3da4 表中,使用聚合操作查询符合以下条件的数据:62c9c6076c186b941274189f 字段值为 "90123c1d-1498-43a4-b96b-001a69fd4bb9",62ccea346123b943f747acf 字段值包含 "0cda5ce1-32139-4c52-b2f4-b324545ccfd1"、"2e0e92ec-a935-43fa-a4a3-5fbdee85c0c0",全表扫描,总耗时为 1043 毫秒
添加索引建议:为 62c9c6076c186b941274189f 和 62ccea346123b943f747acf 字段添加组合索引
日志中表字段ID与工作表字段对应关系
得到工作表ID后可以通过��访问 系统地址/worksheet/工作表ID 进入工作表页面
例如在日志中已知表名称为 ws643e4f73c70d5c2cc7285ce3,去除表名称开头的 ws,643e4f73c70d5c2cc7285ce3就是工作表ID
访问 系统地址/worksheet/643e4f73c70d5c2cc7285ce3 即可进入对应工作表
进入工作表后,应用管理员可以看到应用的 API 开发文档,如下图所示
在API开发文档中有字段对照表
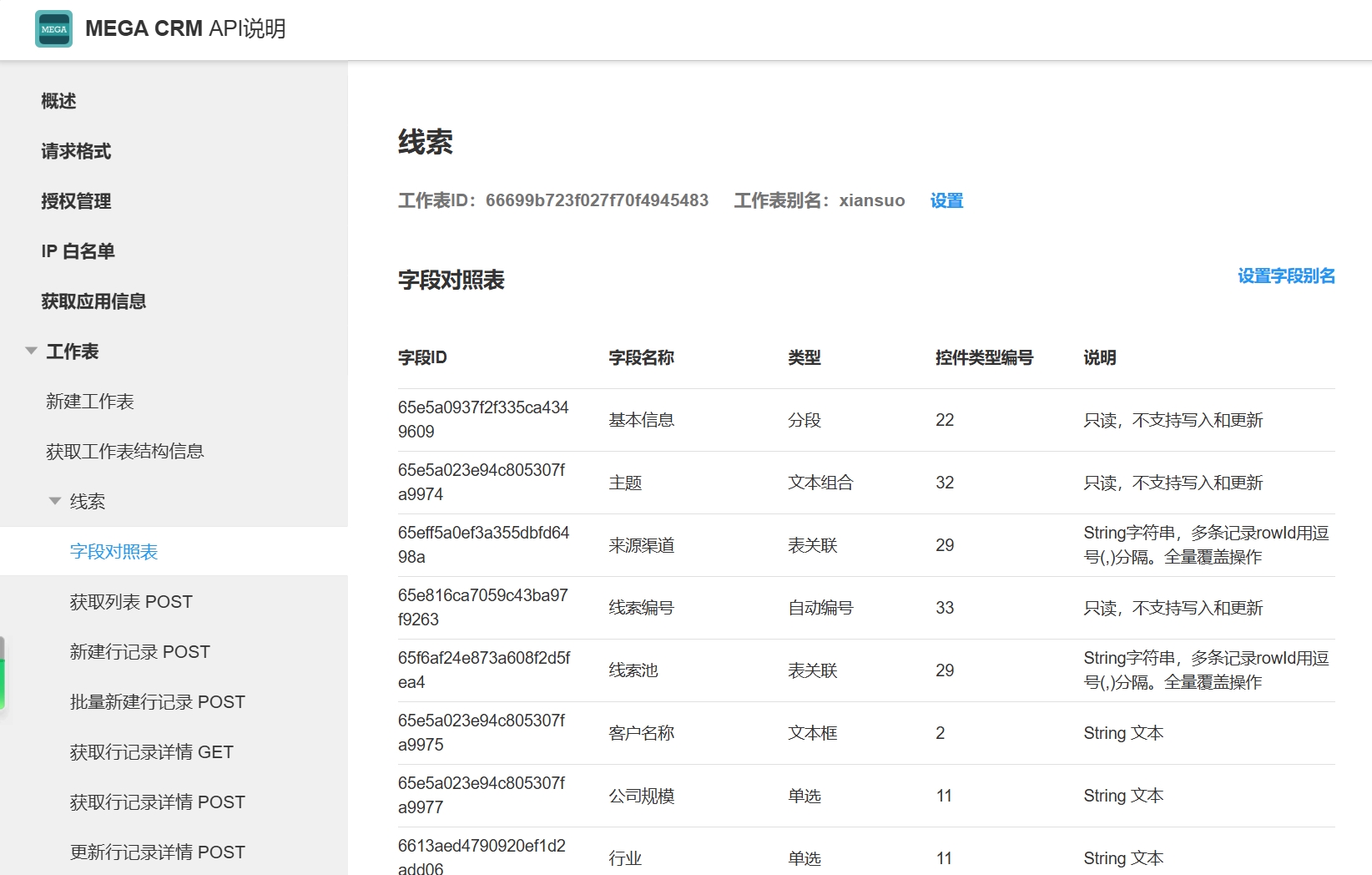
可以通过字段对照表看到字段ID与字段名称的对应关系
添加索引
方式一:工作表配置页面添加
在 API 开发文档中找到字段ID对应的工作表字段后,到工作表配置页面,给对应字段添加索引
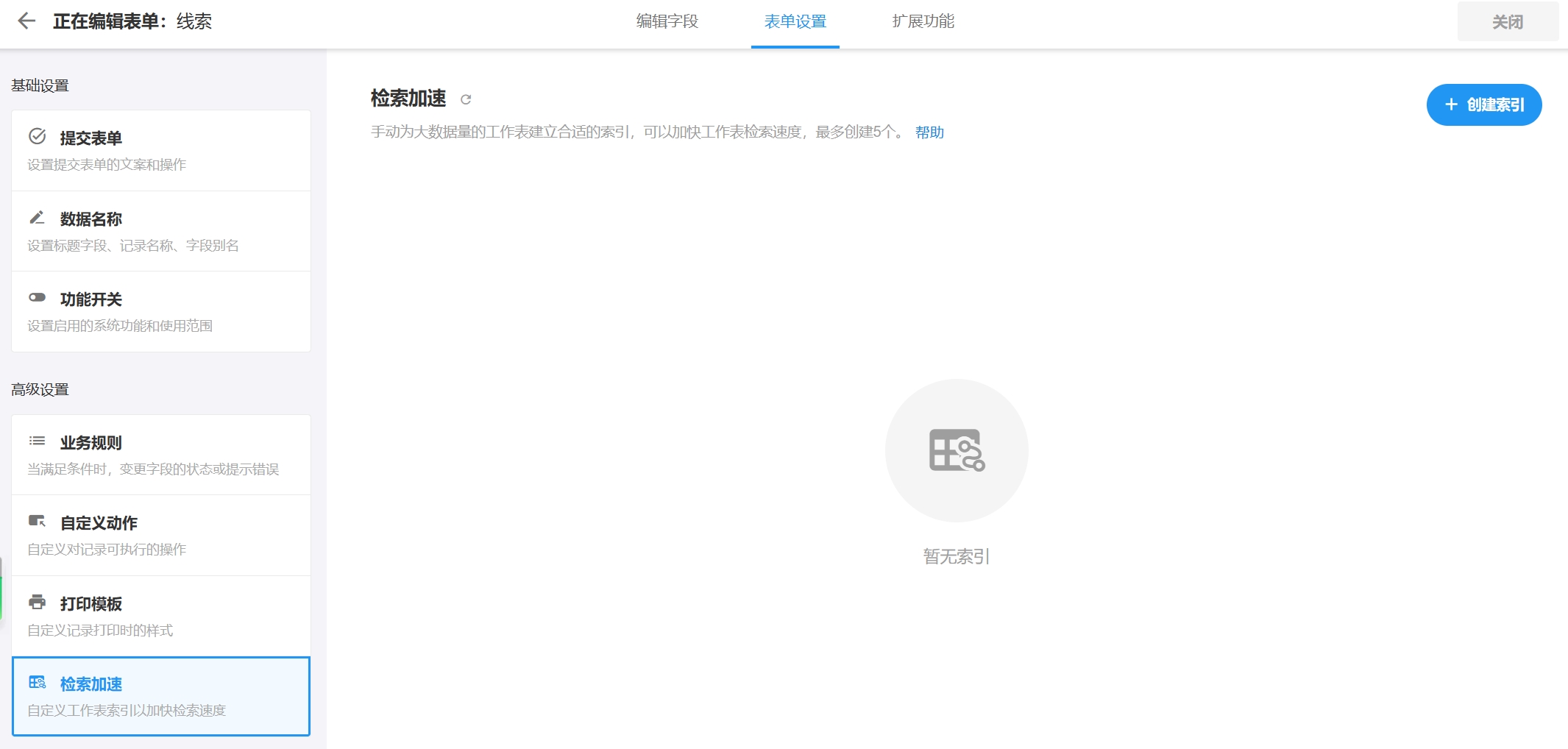
方式二:数据库后台添加
给上面两个示例中提到的表字段添加索引,登录到MongoDB数据库可以执行如下命令
use mdwsrows
db.ws63083dafdf551460042a73.createIndex({"63e0bafdafa62a19751ee00":1},{background: true})
db.ws629f242342bb5f060f3da4.createIndex({"62c9c6076c186b941274189f":1,"62ccea346123b943f747acf":1},{background: true})